AI4TWINNING
Subproject: AI-based / knowledge-driven reconstruction of semantic building data using multiple image data sources
Principle Investigator
Prof. Dr.-Ing. Frank Petzold,
Chair of Architectural Informatics
Project contributor
Alejandro Rueda, M.Sc.,
Chair of Architectural Informatics
Project summary
The usage of buildings changes over time at the district and city levels. This information, and the changes made to it, are significant parameters for urban planning and strategic urban development. However, in digital twins of the built environment, this information is often partially unavailable or not up-to-date. The project focuses on developing a novel data- and knowledge-driven methodology using Deep Learning (DL) methods combined with a Knowledge Base to reconstruct semantic building data. The main focus will be on the automatic identification of types of usage, such as store or pharmacy, based on multiple tagged image data available on the Internet.
Project (preliminary) results
A hybrid pipeline was developed for predicting building usage using facade images from various Internet sources, based on Deep Learning techniques and an ensemble learning approach.
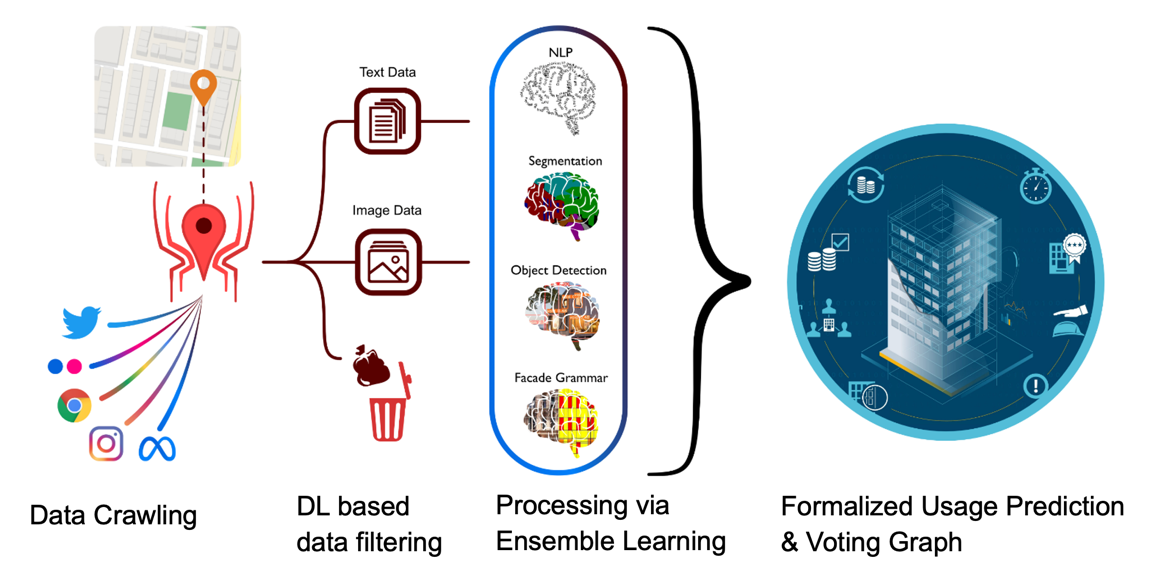
Using currently available object recognition and image classification methods, (usable) facade images are filtered from open access sources such as social media. The filtered data sets are processed in an ensemble learning process, e.g. facade segmentation, object detection and classification using DL methods.
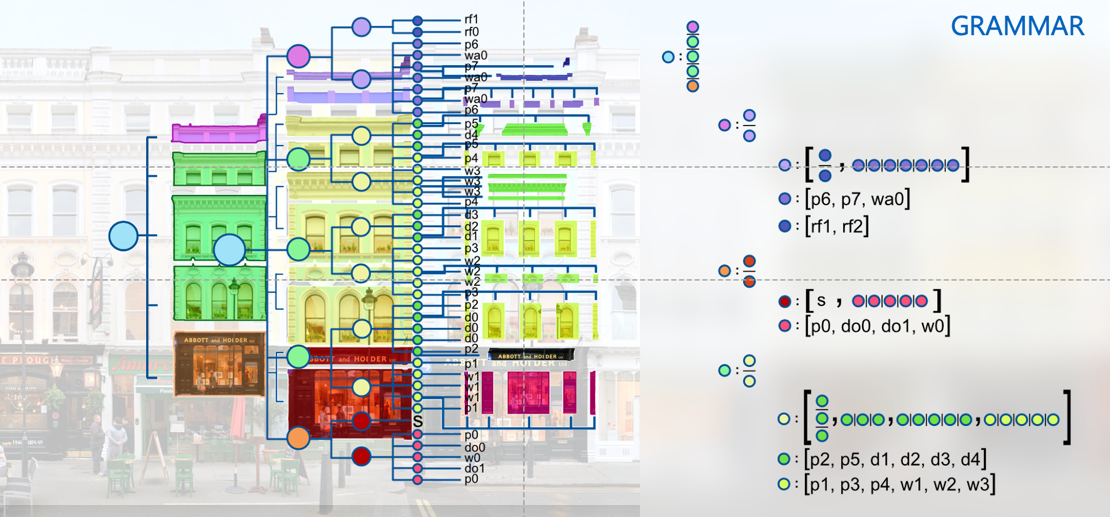
Grammars are extracted using neural networks and information about building usage is predicted by clustering as well as comparisons in the parse tree. We have investigated context-free grammars, such as split grammars and attributed stochastic grammars, and developed a concept to extract architectural features from facade images and generate grammars via Deep Learning. In addition, more textual metadata from images available on social media platforms is analyzed using Natural Language Processing (NLP), such as hashtags and comments. The predicted building usages are transferred to the Digital Twin (DT) and additionally explained by a voting graph.
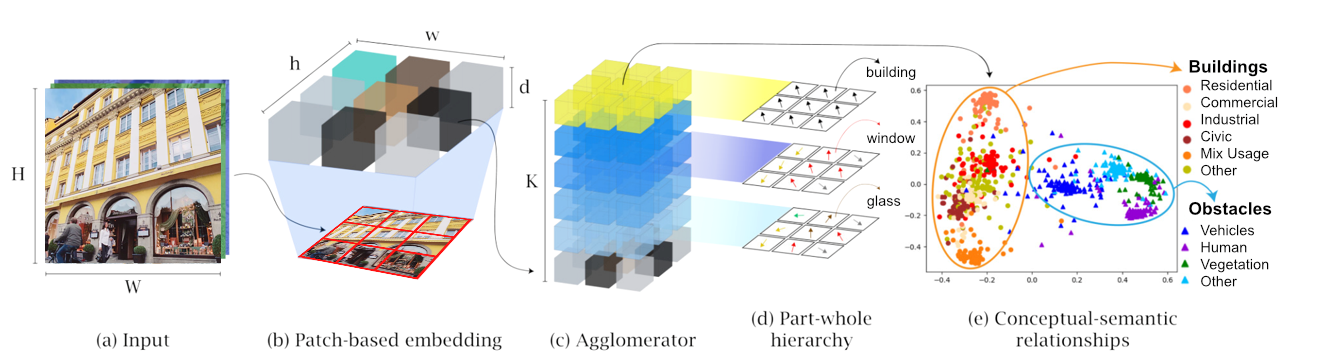
Another aspect of the research was to investigate open access datasets for training to extract grammars from facade images, such as CMP, eTrims, and ECP. However, since these datasets are limited and often insufficient, existing procedural algorithms such as Grammars and Wave Function Collapse, as well as deep generative models such as DatasetGAN, were included in the research to generate synthetic datasets. Annotated Datasets, based on Deep Generative Models, were generated in cooperation with the Chair of Data Science in Earth Observation.