Detection and Classification of Historic Watermarks
Results of this project are explained in the final report.
- Sponsored by: TUM Chair of Geometry and Visualization
- Project Lead: Dr. Ricardo Acevedo Cabra
- Scientific Lead: Dr. rer. nat. Martin Skrodzki
- TUM Co-Mentor: M.Sc. Lena Polke
- Term: Summer semester 2023
- Application deadline 29.01.2023

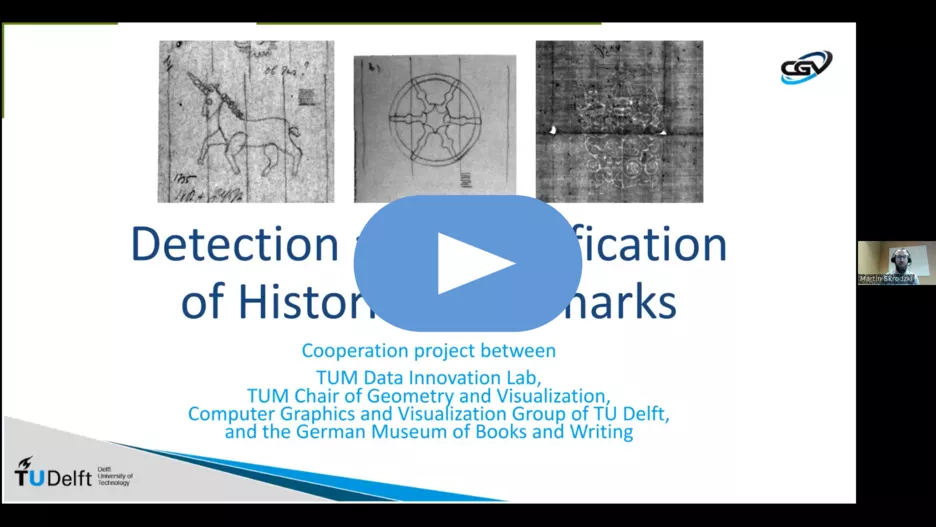
Before paper became available in large quantities via industrial production, paper mills produced small batches for, e.g., books or letters. A paper mill had a strong interest in being recognized, therefore, they placed watermarks on their products. At that time the watermark was created by changing the thickness of the paper and thereby creating a shadow/lightness in the watermarked paper. This was done while the paper was still wet/watery and therefore the mark created by this process is called a watermark. Such marks were first introduced in Fabriano, Italy, in 1282.
The German Museum of Books and Writings, part of the German National Library, has an extensive collection of papers that include watermarks. These watermarks can help to identify the time frame within which, e.g., a letter was written. However, so far, there are only semantic tools available to group and distinguish watermarks, for instance, by a human-made description of the watermark. However, this suffers from the emphasis the respective description makes: What is a main symbol, what is a side symbol? Does the watermark show a standing or a striding lion? These nuances in the semantic descriptions make it extremely challenging to find a set of previously processed watermarks that are, in their appearance, closely related to a given watermark.
The project is intended to create a prototype software to be used in the processing of watermarks at the German Museum of Books and Writings. The goal is to develop a tool for processing of watermark scans, adding of detected watermarks into a database, and (semi-)automatic search for relationships within the processed data. The prototype will likely include the following steps:
- Scans of the watermarks are sent through an image manipulation pipeline to prepare them for feature extraction. This pipeline should get rid of possible artifacts from scanning and should prepare the scans such that the extraction of actual watermark is as easy as possible.
- From the adjusted watermark scans, those parts of the image are extracted that actually represents the watermark. This extracted form should be codified, e.g., via finding a vector graphics representation of it.
- Given two representations of watermarks, determine the likelihood of both representing the same watermark. This should include checking for mirror images, rotations, shearings introduced in the scanning process. Furthermore, a watermark might be represented incompletely, still, a likelihood has to be given. This bears a certain likeness to fingerprint analysis from forensic sciences.
Optionally, the prototype will recognize most common feature elements across the given set of watermarks. These identified elements can then be bound back to the semantic descriptors, thereby identifying common themes, such as geometric elements, certain heraldic symbols, or numerals.
The implemented tool will be the basis for further developments within the German Museum of Books and Writings. Ultimately, it should be extended to a fully interactive database of watermarks to which user can add new elements and use it to compare given watermarks. Therefore, we plan a kick-off event with participating students and supervisors at the German Museum of Books and Writings in Leipzig. Most likely, the prototype will be used in follow-up Bachelor's or Master's thesis investigating these further questions.
There are no strict requirements for participants in the project. However, given the strong visual nature of the project, participating students will benefit from experience with image processing algorithms. Furthermore, for modeling the data, experience with mathematical descriptions of curves, vector graphics, or other representations will be helpful.
Important notice
Accepted students to this project should attend online workshops at the LRZ in April 2023 before the semester starts, unless they have proven knowledge. More information will be provided to students accepted to this project.