PixelDINO: Semi-überwachte semantische Segmentierung zur Erkennung von Permafrost-Störungen
Konrad Heidler
Im Einklang mit dem sich ändernden Klima unterliegt der Permafrostboden raschen Veränderungen. Wenn die Temperaturen steigen, beginnt der gefrorene Boden zu tauen, was verschiedene Folgen hat. Das Auftauen des Permafrosts stellt nicht nur ein Risiko für die lokale Infrastruktur wie Straßen und Gebäude dar, sondern ist auch eng mit dem globalen Klimasystem verbunden, da möglicherweise gespeicherter Kohlenstoff in die Atmosphäre gelangt.
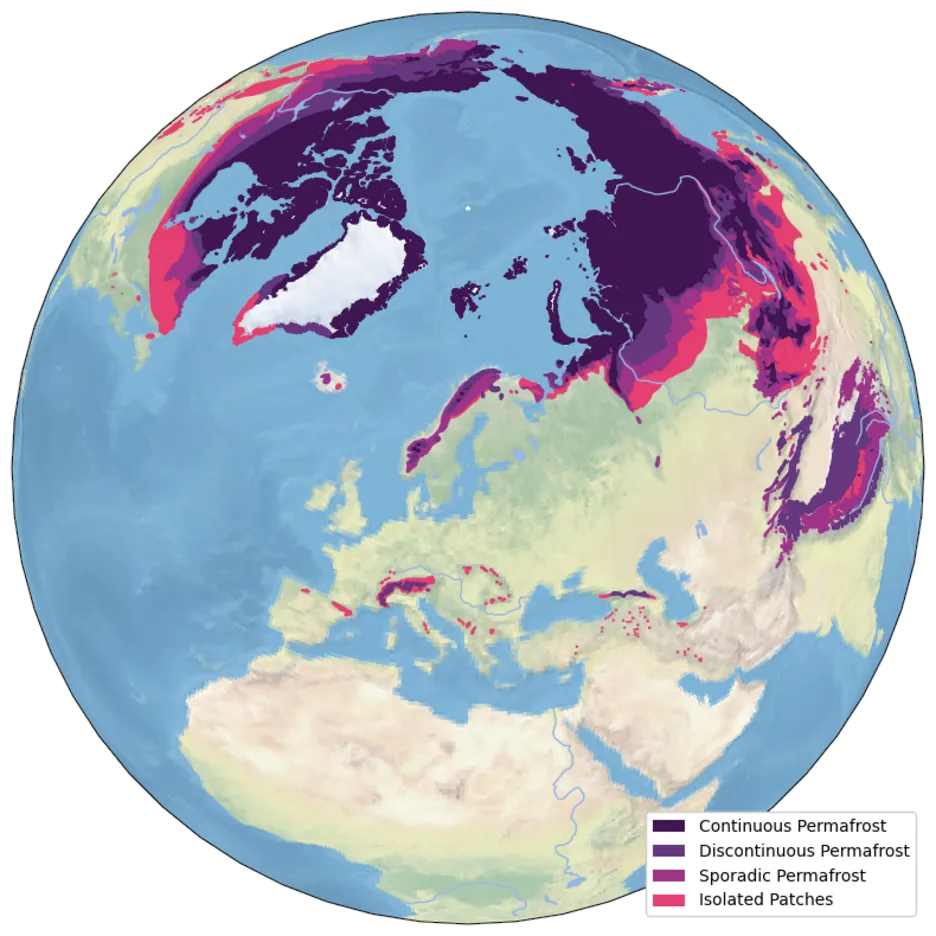
Permafrostgebiete, die mehr als 10 % der Landoberfläche der Erde bedecken, sind oft abgelegen und dünn besiedelt, so dass sie mit herkömmlichen Mitteln nur schwer überwacht werden können. In-situ-Messungen sind auf bestimmte Orte und Zeiten beschränkt, in der Regel wenn Expeditionen diese Gebiete besuchen oder wenn lokale Sensoren Daten sammeln. Um diese Einschränkungen zu überwinden, ist die Fernerkundung eine effizientere Alternative für die Überwachung des Permafrosts.

Permafrost-Fernerkundung
Mit Hilfe von Satellitenbildern können wir leicht Beobachtungen der gesamten Arktis erhalten. Während der Permafrost selbst meist unter der Oberfläche liegt, können wir Indikatoren an der Oberfläche beobachten, die eng mit dem Zustand oder der Verschlechterung des Permafrosts zusammenhängen. Ein Beispiel dafür sind die retrograden Tauabbrüche ("retrogressive thaw slumps", RTS), langsame Erdrutsche, die durch das Auftauen von eisreichem Permafrost entstehen. Trotz ihrer geringen Größe und ihrer verstreuten Verteilung lassen sich RTS aufgrund ihrer ausgeprägten Form und spektralen Signatur auf Satellitenbildern erkennen.
Aber hier ist der Haken: Deep-Learning-Algorithmen sind zwar vielversprechend, wenn es darum geht, RTS auf Satellitenbildern zu erkennen, aber sie benötigen riesige Mengen an Trainingsdaten, die bereits klassifiziert wurden. Tatsächlich ist aber nur ein sehr kleiner Teil der Arktis für RTS klassifiziert worden:
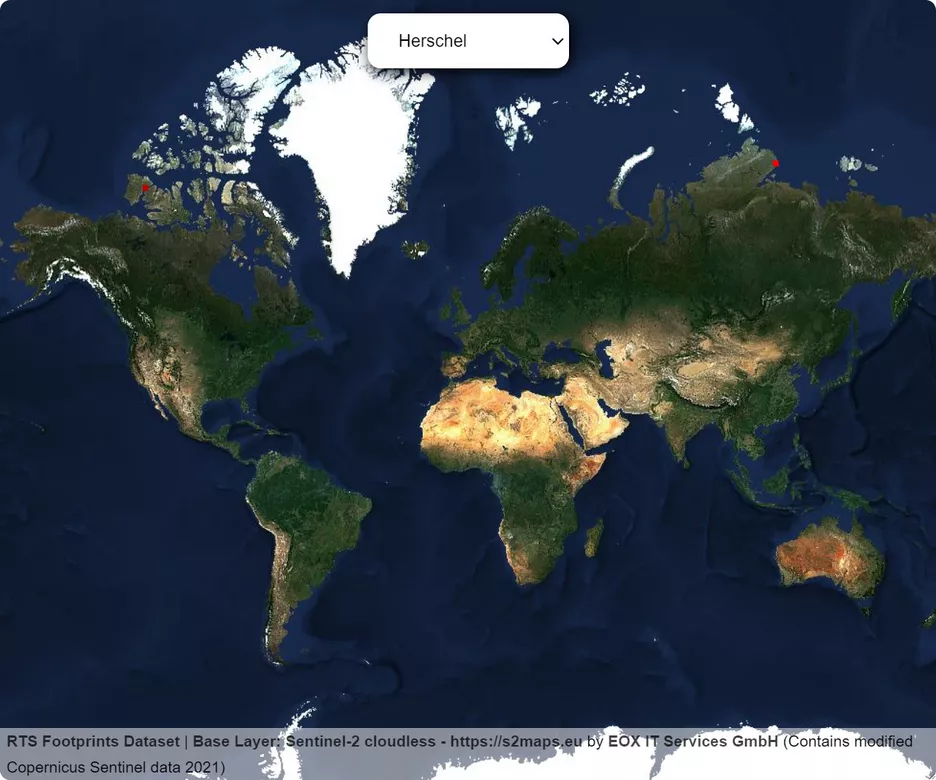
Die Beschaffung von klassifizierten Daten ist kein leichtes Unterfangen, da Permafrost-Experten große Satellitenbildarchive manuell durchsuchen und Beispiele Pixel für Pixel klassifizieren müssen. Natürlich ist es unmöglich, große Teile der Arktis auf diese Weise zu erfassen. Idealerweise suchen wir also nach Möglichkeiten, unsere Modelle auf neue Standorte zu verallgemeinern, ohne dass dafür umfangreiche klassifizierte Daten erforderlich sind. Daher erforschen wir in unserer aktuellen Studie einen neuen Weg, um diese Verallgemeinerungsfähigkeit ohne zusätzliche Klassifizierungen zu verbessern.
Was ist DINO?
Im Idealfall können wir nicht nur die vorhandenen klassifizierten Daten verwenden, sondern dem Modell auch beibringen, Wissen aus nicht klassifizierten Bildern von zuvor unbekannten Regionen zu extrahieren. Dieser hybride Aufbau ist bekannt als halbüberwachtes Lernen.
DINO ist eine Methode zum Trainieren von KI-Modellen ohne klassifizierte Beispiele. Anstatt sich auf von Menschen klassifizierte Daten zu verlassen, lässt es den Computer selbst herausfinden, wie er Objekte in Bildern erkennt und klassifiziert. Intuitiv gibt es dem Netzwerk die folgenden Regeln:
- Jedem Trainingsbild eine Klasse zuweisen
- Sicherstellen, dass die Klassen bei der Transformation des Bildes gleich bleiben
- Verwendung aller verfügbaren Klassen (bei einer vordefinierten Anzahl von ihnen)
Um dies zu erreichen, führt der DINO-Lernprozess zwei Hauptakteure ein: den Schüler und den Lehrer. Sie arbeiten zusammen, um durch einen Prozess, der sich Selbst-Destillation nennt, aus Bildern zu lernen, und achten dabei darauf, die oben genannten Regeln zu befolgen. Der Lehrer beginnt damit, zu erraten, was auf einem Bild zu sehen ist, dann versucht der Schüler, diese Vermutungen zu bestätigen und gleichzeitig aus dem Bild selbst zu lernen. Es ist wie ein Lehrer, der einen Schüler anleitet, aber in diesem Fall sind beide KI-Modelle, die gemeinsam lernen.
Die durch die zweite Regel eingeführten Transformationen werden als Datenaugmentierungen bezeichnet. Durch die zufällige Anwendung von Operationen auf die Eingabebilder können wir das Layout ändern (Spiegeln, Drehen usw.) oder die Bildfarben anpassen (Helligkeit, Kontrast usw.). Während des Trainings sehen sowohl der Schüler als auch der Lehrer unterschiedliche Augmentierungen desselben Bildes. Der Schüler wird dann darauf trainiert, die Klassifizierung des Lehrers zu übernehmen.
Bleibt noch die letzte Regel, nämlich die Erstellung von Modellen, die alle verfügbaren Klassen verwenden. Zu diesem Zweck führt DINO zwei Operationen ein, die Zentrierung und Temperaturskalierung genannt werden. Wie funktionieren diese also? Wenn wir ein Bild eingeben, sagt der Lehrer nicht einfach nur eine einzige Klasse voraus, sondern gibt uns eine Verteilung über die Klassen. Bei der Zentrierung verringern wir die Gewichtung häufig verwendeter Klassen und erhöhen die Gewichtung der weniger häufig verwendeten Klassen. Dies geschieht, indem wir die vergangenen Lehrerausgaben verfolgen. Beim Schritt der Temperaturskalierung werden die Ergebnisse der Lehrer so angepasst, dass die Unterschiede in der Vorhersage hervorgehoben werden - hoch gewichtete Klassen werden noch stärker gewichtet und niedrig gewichtete Klassen werden heruntergeregelt:
Von DINO zu PixelDINO
Im regulären DINO-Schema wird nur eine einzige Klassifizierung für das gesamte Bild vergeben. Für Kartierungsaufgaben in der Fernerkundung benötigen wir jedoch stattdessen eine Klasse für jeden einzelnen Ort im Bild. Das ist es, was wir mit unserem PixelDINO-System tun. Anstatt ganze Bilder zu klassifizieren, weist es jedem Pixel im Bild eine Klasse zu.
Eine Grundannahme des DINO-Trainings ist, dass Augmentierungen die Klassifizierung des Bildes nicht verändern. Wenn man auf der Pixelebene arbeitet, stimmt das nicht mehr! Wenn ein Bild gespiegelt oder gedreht wird, ändern die Objekte im Bild ihre Position. Wir müssen also nicht nur die Bilder für die Schüler augmentieren, sondern auch die Klassifizierungen der Lehrer mitverändern. Hierfür lassen wir uns von einer anderen halbüberwachten Trainingsmethode inspirieren, die FixMatchSeg heißt.
Anstatt zwei zufällige Augmentierungen eines Bildes zu erstellen, baut FixMatchSeg auf einer Kette von Augmentierungen auf. Ein erster Satz, die so genannten schwachen Augmentierungen, wird angewendet, bevor ein Bild an den Lehrer weitergegeben wird. Nachdem die Lehrer-Klassifizierungen für diese Version des Bildes erhalten wurden, wird das schwach augmentierte Bild zusammen mit den Lehrer-Klassifizierungen mit einem zweiten Satz von Augmentierungen, den so genannten starken Augmentierungen, erweitert. Der Schüler trainiert dann, die Ergebnisse des Lehrers mit der stark augmentierten Version des Bildes abzugleichen.
Eine letzte Frage in diesem Zusammenhang ist, wie man die Gewichte des Lehrers lernen kann. Hierfür adaptieren wir die einfache, aber effektive Strategie von DINO: Der Lehrer folgt dem Schüler mit einem exponentiellen gleitenden Durchschnitt. Auf diese Weise ist der Lehrer nicht statisch, sondern wird mit neu destilliertem Wissen aktualisiert.
Von selbstüberwacht zu halbüberwacht
Der nächste Schritt ist die Kombination dieser selbstüberwachten Trainingsmethode mit dem regulären überwachten Training. Wie wir oben gesehen haben, verfügen wir schließlich über Bildmaterial mit vorhandenen Grundinformationen. Da PixelDINO bereits mit Pseudoklassen arbeitet, ist dies sehr einfach! Alles, was wir tun müssen, ist, eine der Pseudoklassen mit der RTS-Klassifizierung abzugleichen, die wir in den Trainingsdaten angegeben haben.
Alles in allem kommen wir zu folgendem Trainingsverfahren für eine einzelne Charge (in Pytorch-Pseudocode):

Ergebnisse
Um zu bewerten, wie gut unsere Methode funktioniert, haben wir mehrere Modelle mit unterschiedlichen Konfigurationen trainiert, um zu sehen, wie gut sie Permafroststörungen klassifizieren. Um den Trainingsprozess so fair wie möglich zu gestalten, zählten wir die Anzahl der Trainingsschritte, die jedes Modell durchlief, anstatt Epochen zu verwenden, da unsere beschrifteten Daten viel kleiner waren als die unbeschrifteten Daten. Wir haben zwei Regionen zum Testen der Modelle ausgewählt: Herschel Island, weil es eine vom Festland isolierte Insel ist, und Lena, weil sie in einer anderen Landbedeckungszone liegt. So können wir feststellen, wie gut die Modelle mit Gebieten umgehen können, die sie noch nie zuvor gesehen haben. Anschließend haben wir die Leistung dieser Modelle mit verschiedenen Konfigurationen verglichen, um zu sehen, welche Trainingsmethoden am besten funktionieren.

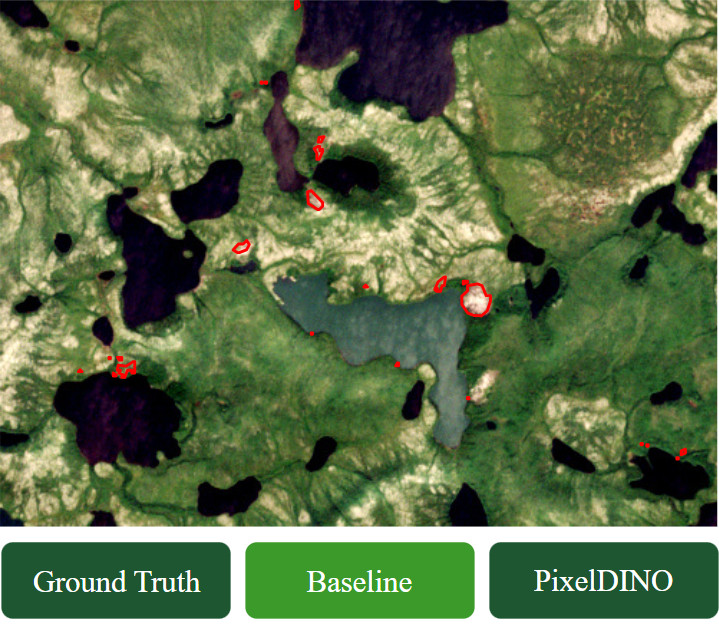
In der Tat übertrifft PixelDINO nicht nur die überwachten Basismethoden, sondern auch die beiden anderen von uns getesteten halbüberwachten Segmentierungsmethoden: FixMatchSeg und Adversarial Semi-Segmentation. In der Praxis führt diese verbesserte Trainingsmethode zu weniger Fehlalarmen und einer genaueren Rekonstruktion der RTS-Formen:
Die entwickelte PixelDINO-Methode sollte sich nicht nur für die Überwachung von Permafrostböden als nützlich erweisen, sondern auch für andere Anwendungsbereiche der Fernerkundung, in denen die räumliche Variabilität eine Herausforderung darstellt. Wir hoffen, dass diese Arbeit zu Folgeforschungen für andere Anwendungen inspirieren kann.