Synthetic Data Generation with GenAI

- Sponsored by: PwC
- Project lead: Dr. Ricardo Acevedo Cabra
- Scientific lead: Oliver Kobsik, Stephan Bautz, Sophie Mutze, Jan-Patrick Schulz
- TUM co-mentor: Prof. Massimo Fornasier
- Term: Summer semester 2024
- Application deadline: Sunday 21.01.2024
Apply to this project here
About PwC
The PwC network spans the globe and employs nearly 350,000 people. As part of the global PwC Network, PwC Germany is well-established in this country having 21 locations and 13.000 employees while we are constantly on the lookout for new colleagues who are enthusiastic about innovation. Everyday PwC Germany is confronted with new challenges and issues, which we always address with our values in mind: We act with integrity, we make a difference, we work together, we care for others, and we reimagine the possible day by day.
In our subcluster 'Data Intelligence/Artificial Intelligence' in Financial Services Transformation Consulting, we advise our clients - multinational banks, insurance companies, and finance-oriented corporates - on the digital transformation of their projects. This includes the areas of Data & Analytics, Big Data, Artificial Intelligence and Generative AI.

About the project "Synthetic Data Generation with GenAI"
Are you interested in addressing data scarcity by developing an innovative approach to generating important and frequently requested data?
Problem statement: Institutions such as banks and insurance companies invest substantial resources, often thousands of hours, in the arduous task of constructing comprehensive databases tailored to meet their diverse business requirements. However, achieving this goal can be a difficult endeavor, marked by numerous challenges and fluctuations in data quality. As an alternative approach, leveraging existing quantified data and statistical information from pre-existing datasets presents a compelling solution with manifold advantages. By using this wealth of information, organizations can generate synthetic data that closely resembles real-world scenarios, providing a versatile resource that can be used for a spectrum of applications.
Synthetic data offers a range of benefits, starting with its ability to protect privacy while maintaining statistical accuracy, which is vital for adhering to data privacy regulations. It also plays a crucial role in testing, development, and machine learning, enabling streamlined processes, innovation, and risk mitigation. Additionally, it supports prototyping and research, ensuring ethical exploration of concepts. Lastly, synthetic data aids in benchmarking and performance testing, allowing organizations to optimize operations and make informed decisions across various scenarios.
In essence, synthetic data emerges as a valuable asset, offering a multi-faceted solution to the persistent challenges faced by institutions in organizing and using comprehensive datasets. Its ability to balance privacy and analytical utility, coupled with its applicability in diverse domains, makes synthetic data a key resource in the data-driven landscape of modern organizations.
In this project, our aim is to explore the frontiers of emerging possibilities by using the wealth of univariate and multivariate data relations. Our objective is to create real-world-like dependencies within the created synthetic data.
To accomplish this, we have at our disposal a versatile toolkit of advanced techniques, including but not limited to GenAI, Copulas, and Monte Carlo Simulation. These cutting-edge methodologies empower us to transcend existing limitations and chart new territories in data modeling and generation. By leveraging these innovative approaches, we can portray complex interrelationships within the data, paving the way for more accurate simulations and insights that were previously unattainable. This endeavor represents a significant leap forward in our ability to replicate and understand real-world dynamics within synthetic datasets, opening doors to unprecedented applications in various domains. In the provided illustration, we have an exemplary representation of the entire project, with the key process occurring within the generation phase.
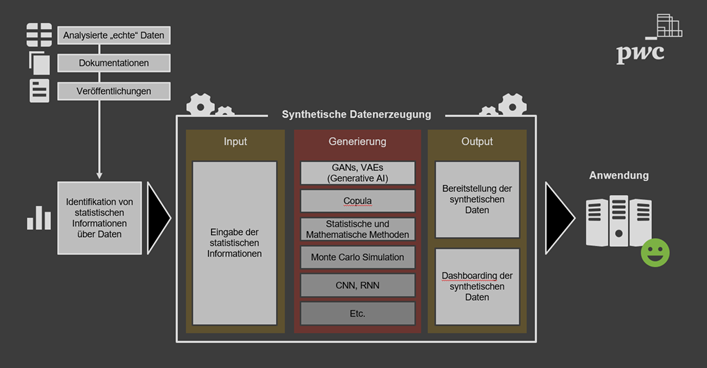
Objective:
The project's overarching goal is to explore new possibilities, conducting a comprehensive analysis of diverse applications. Ultimately, our objective is to not only analyze but also implement a robust methodology that enables the generation of synthetic data closely aligned with the provided statistical information. By doing so, we aim to bridge the gap between theoretical insights and practical application, ushering in a new era of data generation that faithfully mirrors the intricacies of real-world datasets. Through this endeavor, we aspire to empower industries and researchers alike with a powerful tool for various purposes, ranging from privacy-preserving data sharing to advanced model training and scenario testing. We aim to develop at least two solutions, with the initial one showcasing the capabilities of GenAI. This first solution will then be compared against a second alternative to enable a comprehensive analysis of the differences and the resulting outcomes.
Apply to this project here